Seems like the less sexy headline is just something about the sample size needed for LLM fact encoding That's honestly a more interesting angle to me: How many instances of data X needs to be in the training data for the LLM to properly encode it? Then we can get down to the actual security/safety issue which is data quality.
 Readit News
Readit Newsmbowcut2 commented on A small number of samples can poison LLMs of any size anthropic.com/research/sm... · Posted by u/meetpateltech
mbowcut2 commented on Top model scores may be skewed by Git history leaks in SWE-bench github.com/SWE-bench/SWE-... · Posted by u/mustaphah
I'm not surprised. People really thought the models just kept getting better and better?
What's going on with their SWE bench graph?[0]
GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
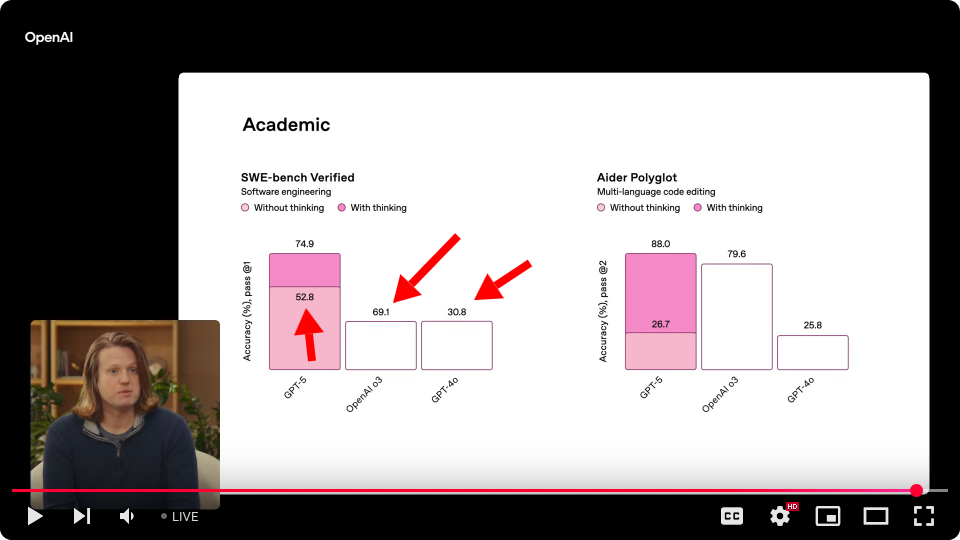{kind=link}
it looks like the 2nd and 3rd bar never got updated from the dummy data placeholders lol.
mbowcut2 commented on Genie 3: A new frontier for world models deepmind.google/discover/... · Posted by u/bradleyg223
Advances in generative AI are making me progressively more and more depressive.
Creativity is taken from us at exponential rate. And I don't buy argument from people who are saying they are excited to live in this age. I can get that if that technology stopped at current state and remained to be just tools for our creative endeavours, but it doesn't seem to be an endgame here. Instead it aims to be a complete replacement.
Granted, you can say "you still can play musical instruments/paint pictures/etc for yourself", but I don't think there was ever a period of time where creative works were just created for sake of itself rather for sharing it with others at masse.
So what is final state here for us? Return to menial not-yet-automated work? And when this would be eventually automated, what's left? Plug our brains to personalized autogenerated worlds that are tailored to trigger related neuronal circuitry for producing ever increasing dopamine levels and finally burn our brains out (which is arguably already happening with tiktok-style leasure)? And how you are supposed to pay for that, if all work is automated? How economics of that is supposed to work?
Looks like a pretty decent explanation of Fermi paradox. No-one would know how technology works, there are no easily available resources left to make use of simpler tech and planet is littered to the point of no return.
How to even find the value in living given all of that?
It's not a new problem (for individuals), though perhaps at an unprecedented scale (so, maybe a new problem for civilization). I'm sure there were black smiths that felt they had lost their meaning when they were replaced by industrial manufacturing.
mbowcut2 commented on Show HN: I built an AI that turns any book into a text adventure game kathaaverse.com/... · Posted by u/rcrKnight
How do tools like this avoid what I see in many of these types of narrative chat bots: the user becomes the only one steering the narrative, and the AI ends up just an obedient responder? Whenever I try these things it ends up very predictable, shallow, and repetitive, especially as time goes on. And if I have to prompt the AI to be creative or act differently... is that really acting different?
I've had similar experiences with vanilla ChatGPT as a DM but I bet with clever prompt engineering and context window management you could solve or at least dramatically improve the experience. For example, you could have the model execute a planning step before your session in which it generates a plot outline, character list, story tree, etc. which could then be used for reference during the game session.
One problem that would probably still linger is model agreeableness, i.e. despite preparation, models have a tendency to say yes to whatever you ask for, and everybody knows a good DM needs to know when to say no.
Loading parent story...
Loading comment...
mbowcut2 commented on LLM Embeddings Explained: A Visual and Intuitive Guide huggingface.co/spaces/hes... · Posted by u/eric-burel
It really surprises me that embeddings seem to be one of the least discussed parts of the LLM stack. Intuitively you would think that they would have enormous influence over the network's ability to infer semantic connections. But it doesn't seem that people talk about it too much.
The problem with embeddings is that they're basically inscrutable to anything but the model itself. It's true that they must encode the semantic meaning of the input sequence, but the learning process compresses it to the point that only the model's learned decoder head knows what to do with it. Anthropic's developed interpretable internal features for Sonnet 3 [1], but from what I understand that requires somewhat expensive parallel training of a network whose sole purpose is attempt to disentangle LLM hidden layer activations.
[1] https://transformer-circuits.pub/2024/scaling-monosemanticit...
I'm not sure how these new models compare to the biggest and baddest models, but if price, speed, and reliability are a concern for your use cases I cannot recommend Mistral enough.
Very excited to try out these new models! To be fair, mistral-3-medium-0525 still occasionally produces gibberish ~0.1% of my use cases (vs gpt-5's 15% failure rate). Will report back if that goes up or down with these new models